背景
水分含量(Moisture content, MC)在海參腌制過程中起著重要作用。較高的MC會導致膠原纖維斷裂,使海參在儲存過程中更容易受損,較低的MC會降低海參的口感和營養價值。準確控制海參腌制過程中MC的含量,對海參的口感品質和商品價值具有重要意義。
大量研究使用高光譜成像(Hyperspectral imaging, HSI)和低場核磁共振(Low field nuclear magnetic resonance, LF-NMR)研究水的遷移和變化并預測MC。HSI是一種用于探測淺水表面物理和化學性質的快速、無損監測技術。LF-NMR是另一種流行的無創檢測技術,用于監測食品中水分狀態的變化和水分遷移。低頻核磁共振之所以有效,是因為當電磁脈沖(Electromagnetic pulse, EMP)在垂直方向輻射時,氫質子由于能量從低能級到高能級的轉變而處于不穩定狀態,而當EMP消失時,這一過程是可逆的。對于海參淺層表面復雜的棘皮結構和內部復雜的腔體、體壁等結構,HSI和LF-NMR聯合檢測可以更準確地預測MC。
深度學習(Deep learning, DL)網絡可以減少模型對人類經驗的依賴,提高模型的泛化能力。CS(Cuckoo search)優化算法通過提取數據的顯著特征實現降維,可以有效提高基于小樣本空間和低類間差異數據的模型性能。因此,本研究基于HSI和LF-NMR數據,采用DL網絡和CS優化算法聯合構建預測模型,對鹽漬海參的MC進行預測分析。
具體研究目標如下:(1)分別針對HSI和LF-NMR數據構建基于變種CS算法的MC深度學習預測模型;(2)通過探索模型的性能,確定了HSI和LF-NMR的*優模型;(3)根據*優模型和核磁共振成像(Magnetic resonance imaging, MRI),分別基于HSI和LF-NMR數據可視化MC分布;(4)構建基于融合數據的MC的Fusion-net DL(FDL)預測模型,并與以往基于單一數據的模型進行比較,選擇*終的*優模型。
試驗設計
大連工業大學王慧慧教授團隊利用Image-λ-N17E近紅外高光譜成像系統(江蘇雙利合譜公司)獲取了510個不同腌制處理下的海參高光譜影像(圖1a)。高光譜數據由350張640×803像素的單波段光譜圖像組成,波長范圍為934.8 ~ 1710.6 nm。如圖1e所示,將鹽漬海參樣品置于核磁共振分析儀(Niumag電氣公司)中進行LF-NMR測,得到如圖1f所示的橫向松弛曲線。每個腌制周期取同一樣品進行MRI分析,通過自旋回波成像序列獲得MC在不同腌制時間的氫質子MRI(圖1g)。
數據的強相關性可能導致“維度詛咒”,有必要對冗余的高維信息進行降維處理。使用CS算法選擇特征,如圖1h所示。針對不同的應用領域,CS有不同的變體,本研究使用的三個變體分別為Traditional-CS(TCS)、Binary-CS(BCS)和Chaotic-CS(CCS)。
將降維后的數據輸入到相應的模型中進行訓練,選擇*優模型(圖1i),實現MC分布變化的可視化(圖1j)。在本文中,MC的預測模型包括基于高光譜數據的單獨DL模型、基于LF-NMR數據的單獨DL模型和基于HSI和LF-NMR數據的FDL模型。對于HSI數據,DL框架中使用了兩個1D卷積層,分別包含32個和64個卷積核,大小為1×3(圖2a)。
對于LF-NMR數據,DL框架的總體結構與上述HSI相同。但對于LF-NMR曲線,除了縱向數值差異外,吸收峰也有明顯的橫向位移。因此,LF-NMR數據比HSI數據更復雜,需要更多的卷積核來提取潛在特征來解決這種復雜的情況。因此,如圖2b所示,將大小為1×3的64、128和256個卷積核組成的三個卷積層應用于LF-NMR預測模型。對于HSI和LF-NMR,分別建立了基于整體和降維數據(W和DR)的MC預測深度學習模型,并討論了它們之間的性能差異。
圖2c給出了MC融合預測模型的融合策略。將約簡后的兩種特征分別放入相應的DL框架中,在flatten層和dense層之間添加concatenate層,將兩種特征合并。

圖1 研究流程圖
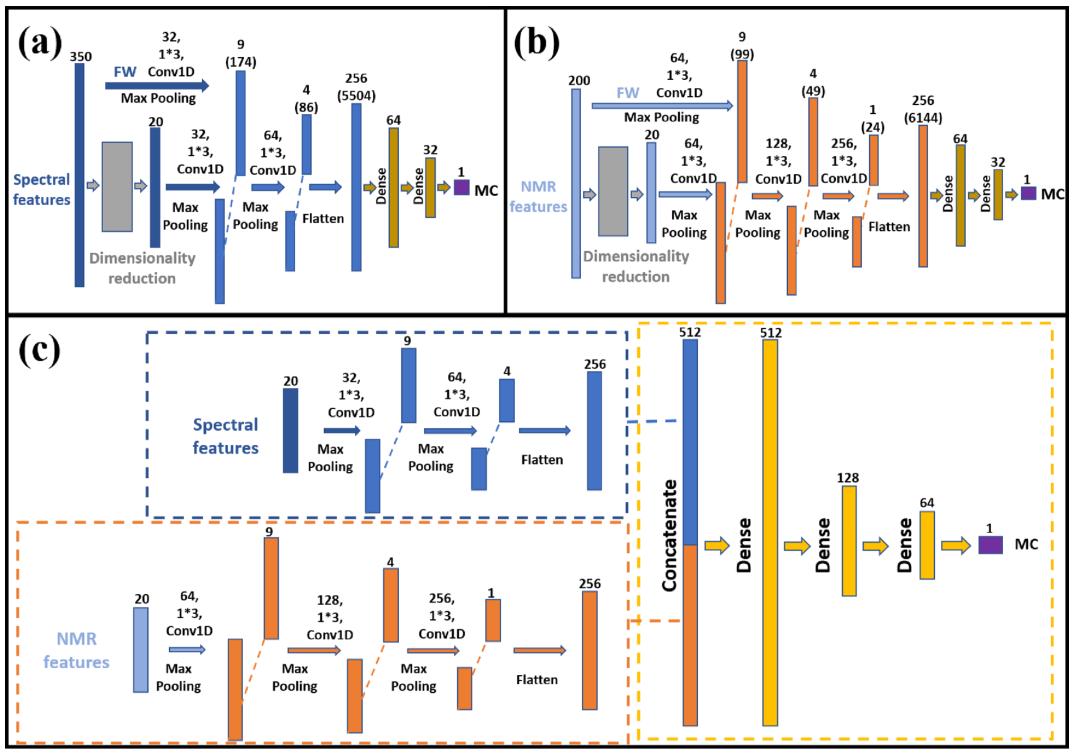
圖2 多種深度學習模型。基于光譜的深度學習模型(a);基于LF-NMR的深度學習模型(b);融合深度學習模型(c)。
結論
圖3為不同腌制階段樣品的光譜反射率變化圖。在圖3a中,不同腌制時間樣品的光譜反射率變化趨勢大致一致。但在1100 nm之前,0 h樣品的反射率值與其他樣品相差很大。可以得出結論,腌制過程的持續時間將是導致反射率變化的重要因素。在960 nm、1190 nm和1430 nm處可以觀察到三個明顯的吸收峰。在圖3b中,平均光譜反射率呈現出與腌制時間相關的變化規律,在960 nm左右,隨著腌制時間的延長,反射率顯著增加,說明樣品內部水分有所降低。在1190 nm左右,反射率逐漸增大,說明海參樣品中的脂質和蛋白質含量在腌制過程中損失較慢。

圖3 不同腌制階段海參樣品的平均光譜反射率曲線
海參樣品在各腌制周期的CPMG弛豫衰減曲線和T2弛豫光譜如圖4所示。如圖4a所示,樣品中質子的衰變速率隨著腌制時間的延長而增加,在前三個腌制階段變化較大。由此可以推斷,在腌制初期,樣品中大量水分流失,樣品中氫質子的含量同時下降,導致質子衰變速率明顯增加。在腌制過程后期,樣品的內部和外部幾乎接近滲透壓平衡,導致MC變化很小。如圖4b所示,在未腌制(0 h)的海參弛豫曲線上存在3個質子弛豫峰,分別為束縛水(T21)、不動水(T22)和游離水(T23)。腌制處理后,T21先減少后消失,T22和T23逐漸減少。隨著腌制時間的增加,海參樣品中的束縛水向右遷移,逐漸變為不動水。不動水向左移動并壓實。隨著時間的推移,游離水也會轉移到剩余的地方,很容易丟失,從而創造了一個抑制微生物活動的環境,這有利于海參的儲存。
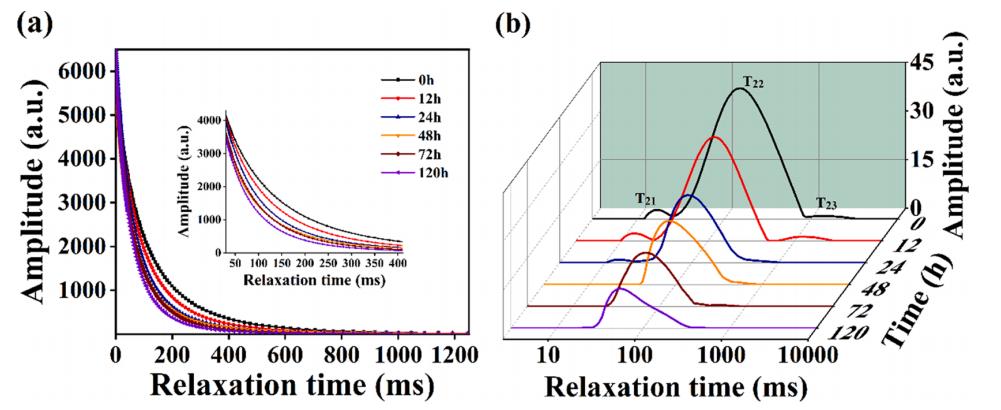
圖4 LF-NMR數據
結合CS降維算法和1D-CNN DL框架,構建了基于HSI、LF-NMR信息的MC預測模型。圖5為基于全部特征的MC估測模型精度圖。證明了DL框架適用于基于HIS以及LF-NMR數據的MC預測。將HSI中所有波長和LF-NMR中時間點對應的數據輸入到FDL框架中進行MC計算。預測效果如圖5e和圖5f所示,可以看到W-FDL具有明顯的優勢。這表明兩類數據在訓練中是相輔相成的,即在單一數據類型中,不可避免的會出現個別數據的異常導致某一樣本的預測失敗,但同一樣本的兩類數據幾乎不可能同時出現異常,這為預測模型的準確性提供了保證。

圖5 HSI-W-DL模型在校準集(a)和預測集(b)、LF-NMR-WDL模型在校準集(c)和預測集(d)、W-FDL模型在校準集(e)和預測集(f)的模型精度。
圖6為三種不同降維算法在HSI數據集中選擇的具體波段,用虛線表示。TCS選擇的20個波段如圖6a所示,在整個波長范圍內分散,既提供了豐富的信息,又降低了相關性。圖6b為BCS算法選取的159個波段,雖然在1000-1050 nm、1200-1250 nm和1500-1600 nm波長范圍內所選波段的密度高于其他地區,但其分布基本覆蓋了整個波長范圍。這意味著所有的特征都包含在選擇的波段中,BCS通過大幅減少數據量來降低計算成本,而不是消除非顯著特征,這可能不利于提高模型的泛化能力,并可能導致過擬合現象。圖6c顯示了CCS選擇的20個特定波段,所選波段在全波長范圍內的分布比TCS更加離散。在優化過程中,前20次迭代HSI-TCS-DL和HSI-CCS-DL的MSE遠小于HSI-BCS-DL,50次迭代后HSI-BCS-DL的MSE沒有減小。同時,自第10次迭代以來,HSI-CCS-DL的MSE約為HSI-TCS-DL的一半,證明混沌映射算法在尋找*優解方面優于隨機算法。
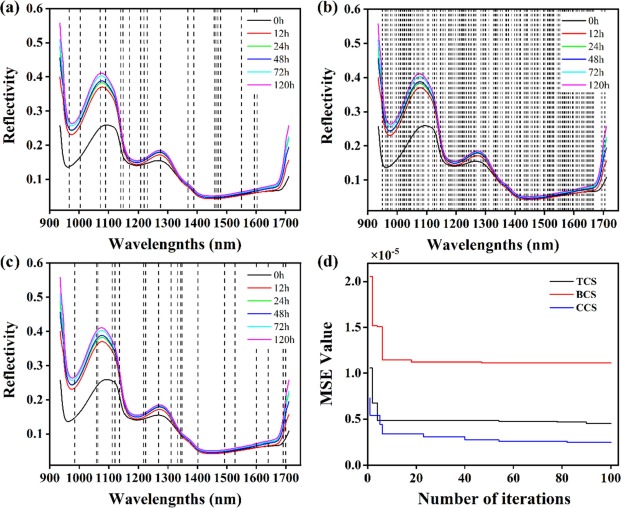
圖6 選自HSI-TCS-DL(a)、HSI-BCS-DL(b)、HSI-CCS-DL(c)模型的具體波段以及HSI-TCS-DL(d)、HSI-BCS-DL(e)、HSI-CCSDL(f)模型的MSE衰減。
圖7顯示了HSITCS-DL、HSI-BCS-DL和HSI-CCS-DL模型的性能。與全數據模型相比,特征約簡后的數據點更收斂于45°直線,對較低MC值的預測效果提高*為顯著。與HSI-W-DL相比,HSI-TCS-DL模型的準確性和穩定性得到了顯著提高,表明降維后的數據更具代表性。雖然HSI-BCS-DL的性能比HSI-W-DL略有提高,但在數據適應性和預測精度方面不如HSI-TCS-DL。與HSI-TCS-DL模型相比,HSI-CCS-DL的性能有所提升,這是因為在CCS降維算法中使用混沌序列初始化種群,有效地解決了模型因隨機初始化而陷入局部*優解的問題。根據上述對比,在HSI數據中,選擇CCS作為*優降維算法,確定HSI-CCS-DL模型為*優模型。
基于HSI-CCS-DL的MC可視化如圖8所示。可以清晰地顯示樣品淺表面同一階段內不同點的MC差異以及不同階段間的變化規律。海參沒有腌制時,基本呈藍色,說明其MC*高。隨著腌制時間的延長,中間區域的顏色由藍色變為綠色,*終變為黃色,同時黃色域逐漸向邊緣擴展。
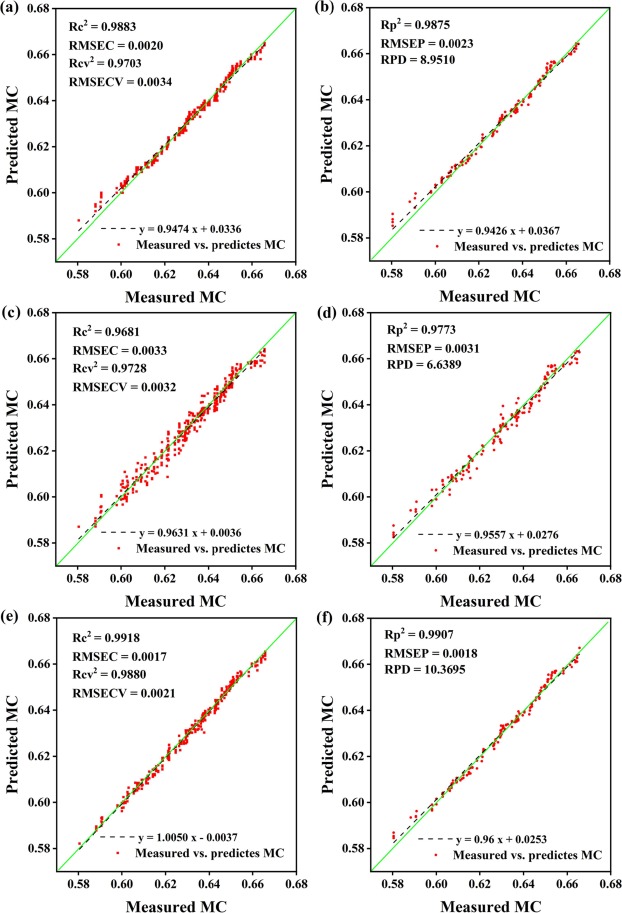
圖7 HSI-TCS-DL模型在校準集(a)和預測集(b)、HSI-BCS-DL模型在校準集(c)和預測集(d)、HSI-CCS-DL模型在校準集(e)和預測集(f)的模型精度。

圖8 基于HSI-CCS-DL模型的海參腌制過程MC分布可視化
圖9詳細描述了LF-NMR-TCS-DL、LF-NMR-BCS-DL和LF-NMR-CCS-DL的特征選擇以及MSE衰減結果。CCS算法是*優的,BCS算法提前收斂,但三種算法的結果差異減小。對于LF-NMR數據,選擇CCS作為*優降維算法,并確認LF-NMR-CCS-DL為*優模型,這與HSI數據的結果一致。

圖9 利用LF-NMR-TCS-DL(a), LF-NMR-BCS-DL(b), LF-NMR-CCS-DL(c)模型選擇的波段以及其MSE衰減(d)。
結合HSI和LF-NMR數據的FDL框架用于海參MC預測。由于前文確定CCS降維算法效果*好,因此選擇CCS和FDL框架構建CCS-FDL模型。如圖10所示,校正集和預測集的R2均達到0.99。在數據點的分布上,圖10a中的訓練集的數據點更加緊湊,更接近真實值,圖10b中的預測集也出現了同樣的情況。FDL框架的優異性能可能是由于HSI和LF-NMR數據之間的互補優勢,即在檢測過程中,同時使用HSI和LF-NMR數據可以大大減少單個數據不準確造成的預測偏差。各模型的比較分析結果見表1。可以看出,對于FDL框架,基于HSI和LF-NMR數據的模型的性能都得到了顯著提高,特別是在整個數據模型中,并且CCS-FDL模型使用40個特征輸入實現了*佳性能。
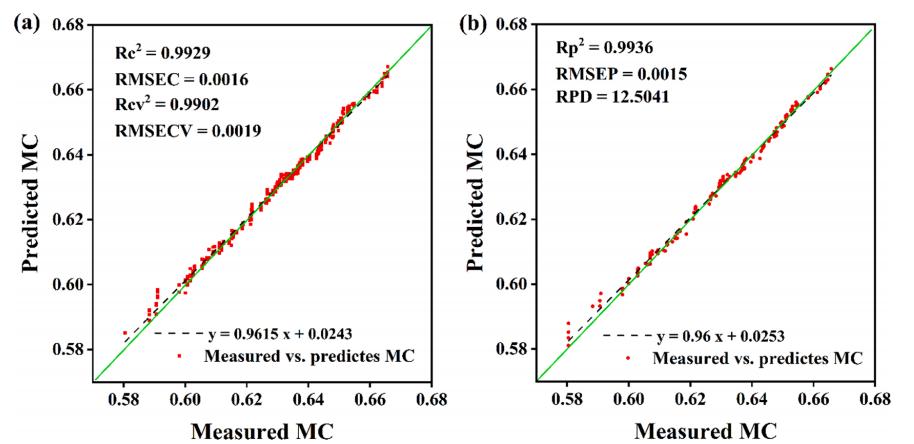
圖10 在HSI和LF-NMR數據集中使用CCS提取特征的FDL模型的預測結果
表1 基于FW、TCS、BCS和CCS的深度學習模型性能

作者信息
王慧慧,博士,大連工業大學機械工程與自動化學院教授,博士生導師。
主要研究方向:基于機器視覺的智能檢測研究、裝備數字化設計。
參考文獻:
Zeng, F., Shao, W., Kang, J., Yang, J., Zhang, X., Liu, Y., & Wang, H. (2022). Detection of moisture content in salted sea cucumbers by hyperspectral and low field nuclear magnetic resonance based on deep learning network framework. Food Res Int, 156.
https://doi.org/10.1016/j.foodres.2022.111174
