背景
高粱在發展中國家作為食糧作物, 在田間種植過程中需要噴撒農藥以減少病蟲害對于產量和品質的影響。當出現嚴重的病蟲害時, 農戶們會多次噴灑高濃度的農藥溶液, 這導致高粱中存在過量的農藥殘留。研究表明, 長期食用農藥殘留超標的食物對人體危害巨大, 會造成癌癥、心臟病、神經性**等嚴重后果。因此, 如何無損、快速、準確檢測高粱中的農藥殘留是亟待解決的問題。
現階段農藥檢測方法包括氣相色譜法、氣相色譜-串聯質譜法、高效液相色譜法等, 這些方法雖然具備較高的檢測準確性和精密度, 但存在制樣復雜、價格昂貴、檢測耗時長、破壞樣品和操作難度高的缺點。近些年來, 研究者們已經開始利用光譜技術來檢測農藥殘留, 常用的方法有拉曼光譜檢測方法[7]、近紅外光譜檢測方法和高光譜成像檢測方法。其中, 拉曼光譜法和近紅外光譜法的檢測精度和靈敏度受環境影響較大。
高光譜技術相比于傳統的光譜技術, 可以同時獲得檢測樣品的圖像信息和光譜信息, 可以實現對農藥殘留的準確檢測。本研究建立了基于BP神經網絡自適應增強算法的集成學習高粱農藥殘留分類模型, 相比于單一分類模型, BP-AdaBoost結合BP神經網絡和AdaBoost算法的優勢, 可以適應不同的數據和問題, 提高模型分類正確率、減少模型過擬合風險。本研究結合高光譜技術與機器學習算法快速檢測高粱中殘留的農藥種類, 可以幫助農產品生產者和食品加工廠快速識別高粱中的農藥殘留種類。
實驗設計
本研究所使用的高粱品種為紅纓子, 是貴州某高粱育種中心常見的品種。農藥選擇高粱種植過程中常用的農藥種類, 分別為苯醚甲環唑、馬拉硫磷、氯蟲苯甲酰胺、莠去津, 分別表示為B、M、L、Y, 購買于四川宜賓某農藥市場。4種農藥分別用蒸餾水稀釋400、700、700、200倍, 配制實驗所需的農藥溶液。用4個噴壺農藥溶液均勻噴灑在4組高粱樣品上, 并設置一組噴灑清水(Q)樣品的對照組。每組樣品包含2880顆高粱籽粒, 共計14400顆。將高粱樣品放置于室內通風處, 自然干燥12 h后利用GaiaField-N17E-HR高光譜成像系統(江蘇雙利合譜公司)采集高粱樣品的高光譜圖像。

圖1高光譜成像系統
采用分水嶺算法分割高粱樣品籽粒,將每顆高粱籽粒所在區域作為感興趣區域提取光譜信息。使用孤立森林算法剔除光譜中的異常值,利用SNV、SG和DWT對光譜數據進行預處理,通過CARS、PCA、CatBoost和GBDT篩選特征波長,建立了XGBoost、LGBM、SVM和 BP-Adaboost農藥殘留分類模型,實現了高粱農藥殘留種類的快速無損檢測。
結論
為顯示不同種類農藥殘留高粱樣品光譜曲線的差異, 計算每類高粱樣品的光譜曲線的平均值得到平均光譜曲線, 如圖2所示。由圖2中可以看出, 在近紅外波段范圍內, 光譜曲線出現3處較為明顯的吸收峰, 分別位于925 nm、1230 nm、1470 nm左右。925 nm位置處的吸收峰與O-H的**拉伸泛頻有關, 1230 nm位置處的吸收峰與C-H的**拉伸泛頻有關, 1470 nm位置處的吸收峰與N-H的**拉伸泛頻有關。在近紅外波段范圍內, 各類農藥殘留高粱樣品的光譜反射率不同, 但總體變化趨勢相似。無農藥殘留高粱樣品的反射率*低, 與不同類型農藥殘留樣品的光譜曲線差異*明顯。此外, B與Y的平均光譜反射率非常接近, L的平均光譜反射率*高。在1000~1100 nm范圍內, 各類高粱樣品的反射率差距*大, 由高到低分別是L、M、Y、B、Q。這些平均光譜的差異為鑒別高粱樣品農藥殘留種類提供了依據。
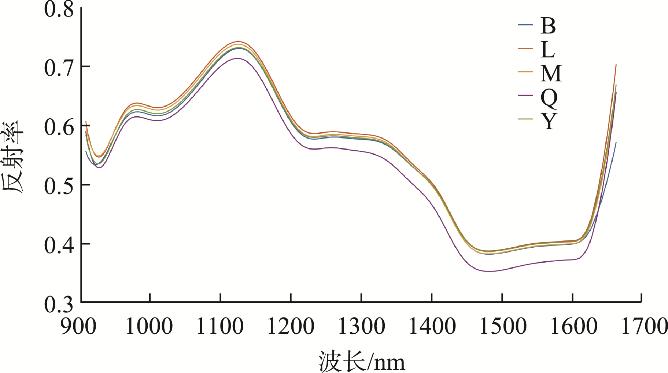
圖2 高粱農藥殘留樣品平均光譜曲線
高粱農藥殘留樣品的光譜曲線在900 nm和1700 nm處出現了異常波動, 這說明這兩個位置處的光譜數據受到的干擾較大, 數據存在嚴重失真的情況。為消除數據失真對后期建模分類效果的影響, 本研究截去了光譜數據開始處前15個和末尾處后41個波段信息, 保留456個波段用于建模分析。利用SG、DWT、SNV預處理方法對高粱農藥殘留樣品的光譜數據進行預處理。建立預處理光譜數據的SVM農藥殘留分類模型識別農藥殘留種類, 識別結果如表1所示。結果顯示, 使用SNV預處理的光譜數據建立的分類模型識別效果好, 訓練正確率和測試集正確率分別為85.94%和81.58%。這可能是SNV預處理可以同時減少噪聲和散射成分對光譜數據的影響。因此, 將SNV預處理后的光譜數據用于后續的研究分析中。原始光譜曲線如圖3(a)所示,SNV預處理之后的高粱農藥殘留樣品光譜曲線如圖3(b)所示。
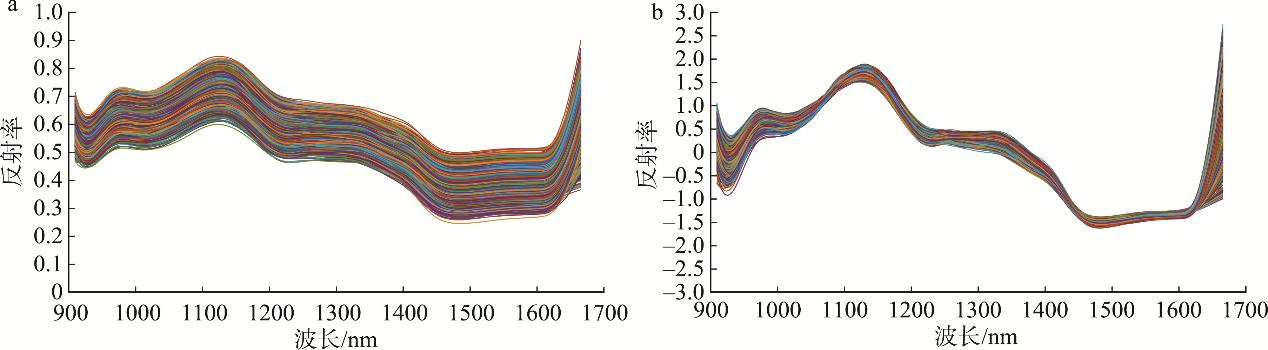
注: a: 原始光譜曲線; b: SNV預處理后的光譜曲線
圖3 高粱農藥殘留樣品光譜曲線
表1 光譜數據預處理后的建模效果(%)
|
方法
|
訓練集正確率
|
測試集正確率
|
|
原始光譜(未處理)
|
82.67
|
81.11
|
|
SG
|
82.77
|
81.43
|
|
DWT
|
82.53
|
81.46
|
|
SNV
|
85.94
|
81.58
|
本研究使用了CatBoost、GBDT、CARS、PCA特征選擇方法, CatBoost和GBDT通過設置特征重要性得分閾值(0.2)選擇特征波長, PCA通過設置載荷系數閾值(0.1)選擇特征波長, CARS選擇建立*小交叉驗證均方根誤差(root mean square error of cross validation, RMSECV)值PLS模型的波長為特征波長, 分別選擇了132、147、35、12個特征波長。圖4為特征波長的具體位置分布圖, 在圖4(a)和圖4(b)中, 綠色線條代表特征波長的具體位置, 紅色線條代表所選擇特征波長對應的特征重要性得分, 特征波長大致分布在900、1100、1400、1650 nm范圍內。其中, CatBoost提取的*大貢獻率波長分布在1600 nm左右, 特征重要性得分為10.23%, GBDT提取的*大貢獻率波長分布在1400 nm左右, 特征重要性得分為4.11%。在圖4(c)和圖4(d)中,紅色線條代表特征波長的具體位置。
表2為不同特征選擇方法篩選的特征波長建立的分類模型結果。全波長模型測試集分類正確率為81.58%, CatBoost-SVM模型測試集分類正確率為81.87%, GBDT- SVM模型測試集分類正確率為81.30%, CARS-SVM模型測試集分類正確率為76.47%, PCA-SVM模型測試集分類正確率為59.19%。特征波長選擇方法效果由高到低分別是CatBoost、GBDT、CARS、PCA, 使用CARS和PCA選擇的特征波長所建立模型的分類正確率有所下降, 這可能是在特征波長的選擇過程中, 減少冗余信息的同時, 也刪除了對建立農藥殘留分類模型有貢獻的光譜數據。研究表明, CatBoost選擇的特征波長不僅可以減少模型的訓練時間, 還能提高模型的分類正確率, 因此, 使用CatBoost選擇的光譜數據用于后續分析。
表2 特征方法的建模結果(%)
|
模型
|
特征方法
|
訓練集正確率
|
測試集正確率
|
|
SVM
|
None
|
85.94
|
81.58
|
|
CatBoost
|
82.40
|
81.87
|
|
GBDT
|
82.04
|
81.30
|
|
CARS
|
77.34
|
76.47
|
|
|
PCA
|
60.68
|
59.19
|
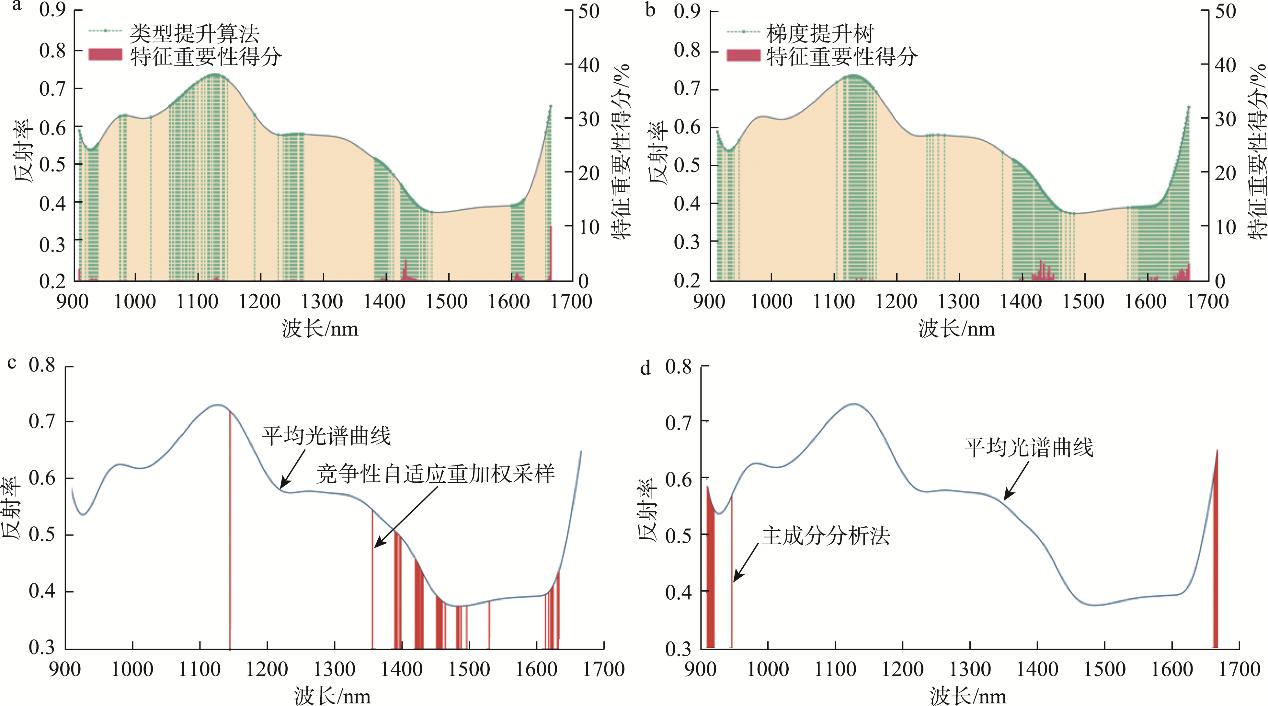
注: a: CatBoost; b: GBDT; c: CARS; d: PCA
圖4 特征波長分布位置
使用CatBoost算法選擇的特征波長為光譜數據, 以實際農藥殘留種類為標簽, 建立光譜數據集, 并使用樣品集劃分方法將光譜數據集劃分為訓練集和測試集, 建立了BP-Adaboost、XGBoost、LGBM、SVM模型, 實現高粱中不同類別的農藥殘留的分類, 建模結果如表3所示。從整體分類結果可以看出, Q的分類正確率*高, 識別效果好, Y的分類正確率*低。*佳的農藥殘留分類模型為BP-Adaboost, 測試集平均分類正確率為95.17%, B、L、M、Q、Y測試集分類正確率分別為99.80%、85.11%、94.76%、99.80%、96.24%, 錯誤識別農藥殘留高粱籽粒顆數分別為1、74、24、1、19。相比于XGBoost、LGBM、SVM模型, BP-Adaboost模型平均正確率分別提升了12.66%、13.47%、13.3%。BP-Adaboost模型之所以取得如此良好的分類結果, 是因為它不僅利用弱分類器組合形成強分類器, 而且還利用BP神經網絡來調整輸入值與輸出值之間的誤差。XGBoost與LGBM模型訓練集分類正確率為100%, 但測試集分類正確率卻較低, 模型出現過擬合現象。本研究針對這個情況使用網格尋優來調整模型的參數, 但分類效果仍然沒有提升, 這可能是由于模型的復雜程度過高而導致的模型過擬合。此外, BP-Adaboost模型建模時間為124.79 s, 雖然相比于XGBoost等模型所需較長, 但與全波長建立的BP-Adaboost模型相比(建模時間為3325.34 s), 極大地降低了模型訓練的時間。與相比姜榮昌等[13]的研究, 在保證單一農藥殘留類別識別率高的基礎上, 同時又提升了模型平均分類正確率。總體來說, CatBoost特征選擇方法結合BP-Adaboost模型可以準確鑒別高粱農藥殘留種類。
本研究利用IF算法剔除了高粱光譜數據集中的異常值, 減少了異常樣品對于建模結果的影響; 使用SNV預處理方法對光譜數據進行預處理, 減少了噪聲和散射成分對于光譜信息的干擾; 在特征波長選擇方面, 使用CatBoost特征選擇方法, 通過計算波長的特征重要性選擇特征波長, 降低了冗余信息對于分類結果的影響, 加快了模型的訓練速度, 特征波長建模效果優于PCA、CARS和GBDT選擇的特征波長; *重要的是使用BP-Adaboost集成學習模型, 結合BPNN與AdaBoost方法, 對多個弱分類器的結果進行集成, 提高了模型的分類正確率, 成功地識別出4組不同農藥殘留的高粱樣品和一組無農藥殘留的高粱樣品, 其中B和Q的分類正確率均為99.80%, 與XGBoost、LGBM、SVM模型相比分別高出了12.66%、13.47%、13.3%, 充分體現出集成學習模型的優勢。綜上所述, 本研究提出了一種新高粱農藥殘留識別方法, 融合高光譜成像技術、CatBoost特征選擇方法和BP-Adaboost集成學習模型, 成功的實現了高粱農藥殘留的快速、無損識別, 模型訓練集平均分類正確率為95.68%, 模型測試集平均分類正確率為95.17%, 為農產品中的農藥殘留種類提供了一種高效、準確的分類解決方案。
表3 特征波長建模結果
|
模型
|
類別
|
訓練集正確率/%
|
訓練集平均正確率/%
|
測試集正確率/%
|
測試集平均正確率
|
時間/s
|
|
BP-Adaboost
|
B
|
99.55
|
95.68
|
99.80
|
95.17
|
124.79
|
|
L
|
86.13
|
85.11
|
|
M
|
95.74
|
94.76
|
|
Q
|
99.95
|
99.80
|
|
Y
|
96.86
|
96.24
|
|
XGBoost
|
B
|
100.00
|
100.00
|
96.39
|
82.51
|
45.49
|
|
L
|
100.00
|
77.47
|
|
M
|
100.00
|
73.91
|
|
Q
|
100.00
|
99.62
|
|
Y
|
100.00
|
63.07
|
|
LGBM
|
B
|
100.00
|
99.55
|
97.41
|
81.70
|
47.82
|
|
L
|
98.62
|
73.68
|
|
M
|
99.59
|
76.16
|
|
Q
|
100.00
|
99.17
|
|
Y
|
99.54
|
63.16
|
|
SVM
|
B
|
97.84
|
82.40
|
97.71
|
81.87
|
47.82
|
|
L
|
71.55
|
70.40
|
|
M
|
78.12
|
74.58
|
|
Q
|
99.44
|
99.61
|
|
Y
|
64.44
|
67.00
|
參考文獻:
張嘉洪,何林,胡新軍等. 基于高光譜成像技術的高粱農藥殘留種類檢測研究 [J]. 食品**質量檢測學報, 2023, 14 (20): 209-217. DOI:10.19812/j.cnki.jfsq11-5956/ts.2023.20.016
